Proyectos de Data Science
Machine learning, análisis estadístico y pipelines de datos — del dataset al insight accionable.
 100k+ órdenes · Analytics Engineering
100k+ órdenes · Analytics EngineeringE-Commerce Data Platform — Olist Brazil
Pipeline de datos end-to-end sobre 100k+ órdenes reales del mercado brasileño (Olist). PostgreSQL + dbt con 4 capas de modelos: staging → intermediate → marts. RFM segmentation, cohort retention, revenue trends y seller performance — todo en SQL puro. Análisis y documentación en portugués (C1). CI/CD con GitHub Actions.
6.500+ mediciones · Privacy-firstAthlete Performance Monitor — Demo Dataset
Dataset sintético de 6.500+ mediciones CMJ/IMTP generado con Python. Faker + numpy con distribuciones calibradas en literatura de sport science. Sistema de alertas neuromusculares con umbrales dinámicos p25/p75 y media móvil de 5 evaluaciones. IDs hasheados desde el origen — 0 datos personales reales.
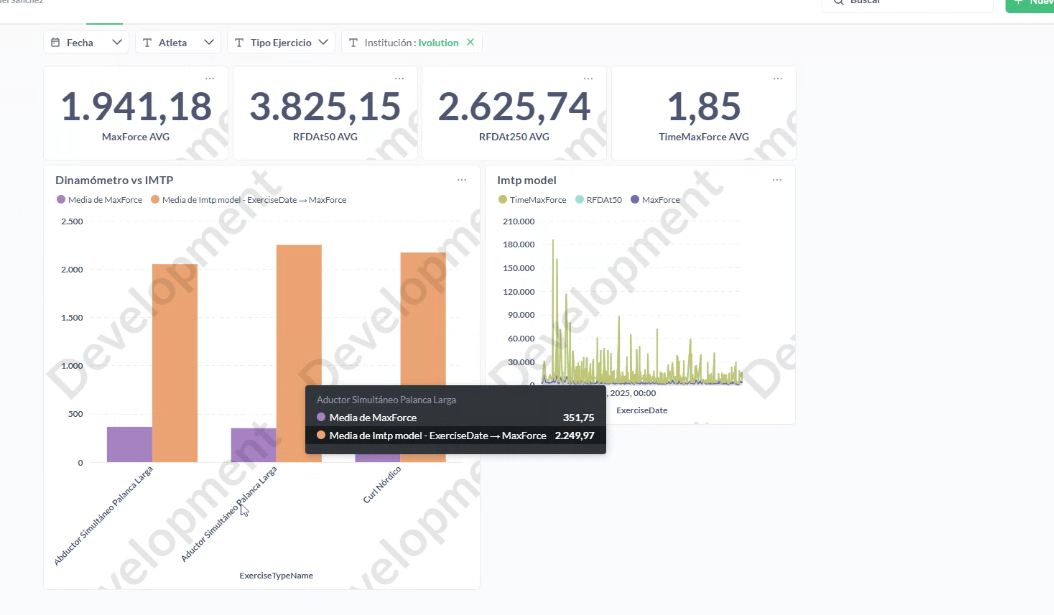 967 atletas · 13 deportes
967 atletas · 13 deportesPerformance Monitoring System — Ivolution
967 atletas monitoreados en 13 deportes. Alertas de tres estados (SUPERCOMPENSACIÓN / ATENCIÓN / FATIGADO) con umbrales dinámicos por percentil (p25/p75), 10.000+ mediciones registradas y soporte multilingüe ES/EN/PT. El sistema continúa operativo tras mi salida — herramienta principal de decisiones de la organización.
 212.292 usuarios · 6 segmentos
212.292 usuarios · 6 segmentosSegmentación de Usuarios — Email Marketing
Segmentación no supervisada sobre 212.292 registros reales de campañas de mailing. Aplica K-Means y MiniBatchKMeans con análisis de Silhouette Score para determinar el k óptimo (6 segmentos). Reducción dimensional con PCA para visualización. Output: archivo Excel con asignación de cluster y recomendaciones de estrategia personalizadas por segmento.
 1.470 empleados
1.470 empleadosIBM HR Analytics — Predicción de Deserción
Análisis end-to-end sobre el dataset oficial de IBM con 1.470 empleados. Identifica los factores con mayor impacto en la rotación laboral mediante Random Forest con matriz de confusión y métricas de clasificación. Segmentación con K-Means y visualización de clusters con PCA. Genera insights accionables para reducir el churn de RR.HH.
 27.290 reseñas
27.290 reseñasNLP & Sentiment Analysis — Yelp Reviews
Pipeline completo de Procesamiento de Lenguaje Natural sobre 27.290 reseñas reales de Yelp (2005–2015). Análisis de sentimiento con TextBlob, Topic Modeling con LDA (5 temas: restaurantes, hotelería, retail, comida casual, cocinas especiales) y clustering semántico con K-Means sobre matriz TF-IDF. Insight clave: las reseñas más largas tienen sentimiento más negativo.
 Dataset Kaggle
Dataset KagglePipeline de Preprocesamiento — Weather AUS
Pipeline robusto sobre el dataset climático de Australia de Kaggle. Imputación estratégica de valores faltantes, encoding de variables categóricas, feature engineering y estandarización con StandardScaler. Base sólida y reproducible lista para cualquier modelo de clasificación de lluvia.
 80+ variables · 84% accuracy
80+ variables · 84% accuracyHouse Price Prediction — Kaggle
Modelo de regresión sobre el dataset clásico de Kaggle con más de 80 features de propiedades residenciales. Pipeline completo: EDA, imputación de nulos, encoding, feature selection y modelado. Competencia clásica de regresión supervisada con variable objetivo SalePrice.
 2.000 canciones · 59 géneros
2.000 canciones · 59 génerosSpotify Music Analysis — EDA
Análisis exploratorio sobre 2.000 canciones de Spotify (1998–2020) con 59 géneros musicales. Correlación entre features de audio: danceability, energy, valence, tempo, instrumentalness. Visualizaciones de tendencias de popularidad por género y evolución temporal de las características musicales.
Jupyter Notebooks & más análisis
Explorá todos mis notebooks y proyectos de análisis de datos en GitHub.